Consolidate Multiple Workloads with a Single Database
MariaDB Enterprise Server includes multiple storage engines to consolidate a variety of database workloads – everything from write-intensive (e.g., IoT) to scalable key/value (i.e., NoSQL) workloads – without sacrificing performance, scalability and flexibility.

Using workload-optimized storage engines to improve performance
In this webinar, we walk through the various storage engines in MariaDB Enterprise Server, and explain how to improve the performance and scalability of different workloads by using the right one (or combination).
Watch NowPluggable Storage Architecture
MariaDB Enterprise Server implements a pluggable storage architecture because different workloads have different storage characteristics. The optimal data structure for mixed read/write workloads is not the best for write-intensive workloads and vice versa. The same is true for transactional vs. analytical workloads. By allowing different database instances or tables to use different storage engines, MariaDB Enterprise Server can support a variety of workloads equally well – and without compromising scalability, flexibility or performance.
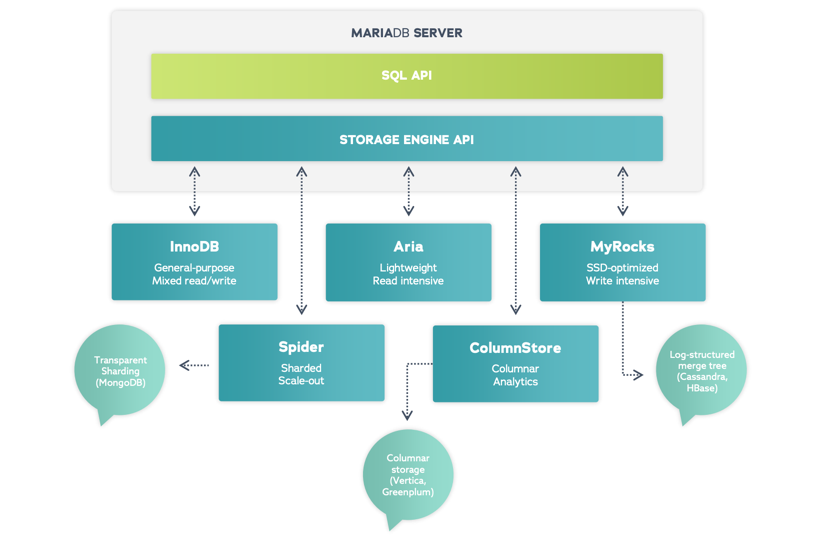
One Database. Every Workload.
InnoDB
InnoDB is the default storage engine in MariaDB Enterprise Server, and supports compression, encryption and instant schema changes. In addition, InnoDB is required for multi-master clustering with synchronous replication. It is a general-purpose storage engine ideal for mixed read/write transactional workloads.
MyRocks
The MyRocks storage engine, developed by Facebook, was engineered for write-intensive (and space-intensive) workloads, with better compression and less write amplification than InnoDB. MyRocks is a fork of RocksDB, a high-performance storage engine developed by Google and optimized for SSDs and multi-core processors.
Aria
Aria is a crash-safe, non-transactional storage engine for MariaDB Enterprise Server. It is the storage engine used by system tables, and is well suited to workloads where read performance is critical. For example, it's ideal for shopping carts and reviews/ratings, where performance is more important to customer engagement than the ability to roll back transactions.
Spider
Spider is a virtual storage engine for sharding data in the same way as MongoDB. It uses standard partitioning schemas such as list, range and hash to distribute partitions across multiple database instances. Spider can be used with InnoDB to scale out mixed read/write workloads or with MyRocks to scale out write-intensive workloads.
ColumnStore
ColumnStore – unlike the other storage engines but like Vertica and Greenplum – stores data in a columnar format and separately from the database itself. The data is distributed across multiple servers to support ad hoc queries on hundreds of billions of rows in real time without creating indexes and/or a snowflake schema.
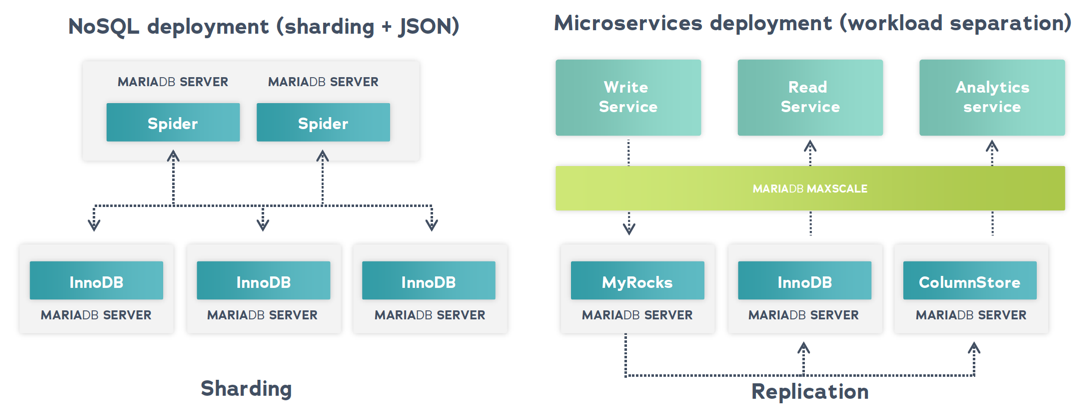
Combine Multiple Storage Engines to Meet Architectural Requirements
The storage engines in MariaDB Enterprise Server can be combined to meet the performance and scalability requirements of any application. In the example below (left), Spider is combined with InnoDB to scale out reads, writes and storage. This combination can be used with the JSON data type to create a NoSQL deployment – scalable and flexible. In the second example (right), to support various microservices, the same data is stored in different storage engines: MyRocks for writes, InnoDB for reads and ColumnStore for analytics.