
If your organization wants to use ServiceNow, but has security, regulatory, or privacy requirements which make ServiceNow Cloud non-viable, then you’re going to need to deploy self-hosted ServiceNow to your organization’s secure datacenter(s). While ServiceNow gives you all the instructions and help you’ll need to get the application components setup and running for that, your self-hosted setup won’t work without an attached, relational database. ServiceNow provides “compatibility” for many RDBMS solutions, but you know there’s a big difference between a “compatible” solution and a solution which has been well-tested and validated for your use-case. Not only does ServiceNow rely on MariaDB Server for its massive ServiceNow Cloud, but ServiceNow also extensively and rigorously tests MariaDB Enterprise Server to ensure not just compatibility, but performance, security, and reliability for self-hosted ServiceNow use-cases.
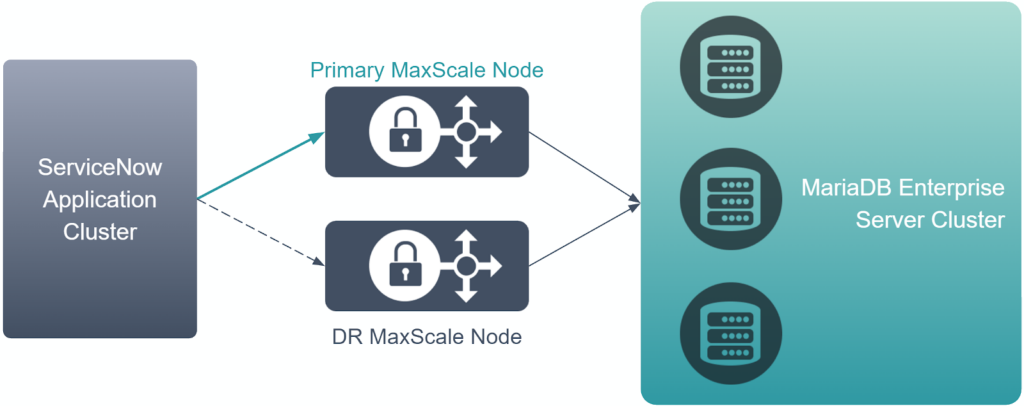
Neither you nor your organization are going to be content deploying a single MariaDB Enterprise Server instance and hooking your self-hosted ServiceNow application to it. You’ve already followed ServiceNow’s instructions for deploying multiple application nodes in a highly available cluster to safeguard your deployment’s uptime. But that means nothing if your attached database goes down or loses network connectivity, because your self-hosted ServiceNow application can’t operate without its database. Unfortunately, the instructions you’ve received don’t include how to add High Availability or Disaster Recovery functionality to your attached database.
Luckily, MariaDB has already solved this problem. MariaDB MaxScale’s high availability features give you the tools you need to achieve high availability. This is an excellent first step towards making your ServiceNow database cluster resilient to failures. But you may wonder- if MaxScale adds resilience to your MariaDB database backends, what adds resilience to MaxScale?
Setting-up MaxScale to enable Cooperative Monitoring
MaxScale comes built-in with Cooperative Monitoring. This allows multiple MaxScale nodes to manage the same MariaDB Server backends without conflict. It does not matter if the MaxScale nodes are in the same datacenter or on the other side of the world from each other.
To enable this functionality, you’ll need to setup MariaDB Monitor in MaxScale to include each of your MariaDB Server backends used for your ServiceNow database cluster. Then, inside your MariaDB Monitor configuration block, you’ll add cooperative_monitoring_locks = majority_of_running. An example MariaDB Monitor block is shown below-
[MariaDB-Monitor] type=monitor module=mariadbmon servers=east-db1, east-db2, west-db1, west-db2 user=maxscale_monitor password=Replace_with_Str0ng_P@ass0rd_H3r3 replication_user=repl_user replication_password=Replace_with_Str0ng_P@ass0rd_H3r3 enforce_read_only_slaves=true verify_master_failure=true auto_failover=true cooperative_monitoring_locks=majority_of_running
Again, the above is just an example, and you should adjust all parameters based on your use-case and needs. Please refer to our documentation to understand what options are available for MariaDB Monitor and what each controls.
Make sure cooperative_monitoring_locks = majority_of_running is configured on all MaxScale nodes you intend to manage your same MariaDB Server backend cluster. With this setup, your MaxScale nodes will coordinate with each other to ensure all nodes identify the same backend node as primary, and it will also ensure your MaxScale nodes properly handle failover and new primary selection.
Finally, be sure to restart each MaxScale node after setting cooperative_monitoring_locks = majority_of_running in its configuration file. If you’d like to configure this without restarting MaxScale, you may dynamically configure this with maxctrl, MaxGUI, or MaxScale’s API.
Setting-up MaxScale Routing for ServiceNow
If you have already been using MaxScale, you may have this setup already, but just to be sure we’ll walk back through best-practice for configuring MaxScale to route for ServiceNow.
For this example, we’ll use MaxScale’s Read/Write Split Router which integrates well with MariaDB Monitor and adds the ability to safely send some read queries to replicas to help horizontally scale MariaDB Server backend performance. Below is an example configuration-
[Splitter-Service] type=service router=readwritesplit cluster=MariaDB-Monitor user=maxscale password=Replace_with_Str0ng_P@ass0rd_H3r3 master_reconnection=true transaction_replay=true master_failure_mode=error_on_write connection_timeout=900s slave_selection_criteria=ADAPTIVE_ROUTING delayed_retry=true delayed_retry_timeout=60s master_accept_reads=true causal_reads=global causal_reads_timeout=3s
Please refer to our documentation to understand what options are available for MariaDB Read/Write Split Router and what each controls.
Configuring Causal Reads in MaxScale for ServiceNow
One requirement for ServiceNow-specific use-cases will be to configure MariaDB Read/Write Split Router to enable causal read support. There are a few values for this, but for ServiceNow purposes, there are only three-
fast_globalglobaluniversal
The safest option is universal– this ensures consistency even when multiple MaxScale nodes are handling queries at the same time. However, universal can be slow as it involves an extra round trip, so if you enable this and find performance to be a problem, then one of the two global options may be better.
Note that in order to use either global option, when you configure your ServiceNow database connection strings (covered later in this article), every ServiceNow application must have the same MaxScale nodes in the same order. This would help ensure that only one MaxScale node is handling queries at a time, which is important because global ensures causal read support only for queries running on the same MaxScale node.
Which global option should you use if universal isn’t viable for you? global_fast should deliver better latency, but most queries will run on the primary. global may increase latency a little bit, but has a better chance of sending a higher percentage of read queries to replicas. If your primary MariaDB Server backend is running at capacity, then global is likely a better option. However, if your primary MariaDB Server backend has plenty of headroom, then global_fast is the way to go. Our documentation offers more details on these options if you’d like to read deeper.
Configuring ServiceNow Application to enable Highly Available connectivity to MaxScale
Many MariaDB connectors, like the JDBC ServiceNow’s application relies on, support extended functionality called “High Availability Modes”. To access this functionality for ServiceNow, you’ll want to find your glide.db.properties file on each of your ServiceNow application nodes. The default directory path should be something like this on Linux-
/glide/nodes/${node}/con/
Where ${node} will change based on the naming of your ServiceNow application node.
Once you’ve located the file, use your favorite text editor to open the file and find the glide.db.url line. This line should look something like the below (where ${active-maxscale-ip} and ${port} are placeholder variables which will be specific to your file)-
glide.db.url = jdbc:mysql://${active-maxscale-ip}:${port}/
The key change you’ll make is to replace mysql with mariadb:sequential. With this, you’ll be able to specify more than one MariaDB host and port combination. You’ll want to have a list of your MaxScale nodes’ IP addresses and/or hostnames handy, alongside the port you’ve set them up to listen for ServiceNow database connections on. You’ll then input those separated by a comma. For the below example, you’ll want to substitute ${maxscale-1-ip} with the IP address or hostname of the MaxScale node you’d like the ServiceNow application to try connecting first to. You’ll likewise need to replace ${maxscale-1-port} with the listening port that corresponds to that MaxScale node (3306 is default). While the below example only specifies two MaxScale nodes, you can add as many as you want (separated by a comma)-
glide.db.url = jdbc:mariadb:sequential://${maxscale-1-ip}:${maxscale-1-port},${maxscale-2-ip}:${maxscale-2-port}/
When you’re done making your changes, save the file. Apply this change to all other ServiceNow application nodes as well. Then restart your ServiceNow application cluster for the change to take effect.
Fine-tuning this for your topology
In most cases, you’ll want to set up jdbc:mariadb:sequential so your MaxScale nodes are in the same order on every ServiceNow application node/cluster. This maximizes stability and compatibility.
However, if you have ServiceNow application nodes or clusters in multiple, geographic regions, and you likewise have MaxScale nodes in multiple, corresponding geographic regions, then it would be smarter to change the order for each region so the MaxScale node(s) from the same region are put ahead of MaxScale nodes from other regions. Note if you do this and you have a complex ServiceNow application cluster setup where you route traffic to multiple regions at the same time, you’ll need to use causal_reads=universal in MaxScale to ensure compatibility with ServiceNow.
Sample configuration file
The below global configuration file for MaxScale puts together the above concepts with the other, needed configuration blocks. This may provide a helpful guide for putting together your own MaxScale configuration file to take advantage of these concepts.
# Global MaxScale variables [maxscale] # Automatically spin-up threads equal to detected logical CPU core count threads=auto # Recheck the load of worker threads every 10 seconds and rebalance workload accordingly rebalance_period=10s # Setup for MaxGUI and TLS/HTTPS admin_host=0.0.0.0 admin_secure_gui=true admin_ssl_version=MAX admin_ssl_key=PATH_TO_SSL_KEY admin_ssl_cert=PATH_TO_SSL_CERT # Setup MaxScale configuration synchronization cluster so all MaxScale nodes use the same configuration config_sync_cluster=mxs config_sync_user=maxscale_sync config_sync_password=REPLACE_ME # Define how to connect to each MariaDB Server backend MaxScale will manage [east-db1] type=server address=IPV4_ADDRESS_HERE port=3306 protocol=MariaDBBackend proxy_protocol=true [east-db2] type=server address=IPV4_ADDRESS_HERE port=3306 protocol=MariaDBBackend proxy_protocol=true [west-db1] type=server address=IPV4_ADDRESS_HERE port=3306 protocol=MariaDBBackend proxy_protocol=true [west-db2] type=server address=IPV4_ADDRESS_HERE port=3306 protocol=MariaDBBackend proxy_protocol=true # Define MariaDB Monitor [MariaDB-Monitor] type=monitor module=mariadbmon # Specify the servers (based on server object blocks above) for this MariaDB Monitor object to include servers=east-db1, east-db2, west-db1, west-db2 # MariaDB Monitor needs a MariaDB user on the MariaDB Server backends, so provide username and credentials to connect user=maxscale_monitor password=REPLACE_ME # Note you could make one MaxScale user with permissions for monitoring, replication, etc... # But here we're using individual users for each purpose, so this sets the credentials to connect to the replication user replication_user=repl_user replication_password=REPLACE_ME # Use the below to have MaxScale automatically set replicas to read_only when performing primary failover/switchover operations # This helps minimize the risk of users writing directly to replicas and causing data desynchronizations or other problems enforce_read_only_slaves=true # Follow this link to learn more about this setting- https://staging-mdb.com/kb/en/mariadb-maxscale-2302-mariadb-monitor/#verify_master_failure-and-master_failure_timeout verify_master_failure=true # Configure MariaDB Monitor to automatically failover a failed primary and to automatically rejoin a formerly failed primary when feasible auto_failover=true auto_rejoin=true # THIS IS REQUIRED TO ENABLE COOPERATIVE MONITORING which keeps multiple MaxScale nodes in-sync on what backend is the current primary and what MariaDB Monitor instance is allowed to perform cluster management operations cooperative_monitoring_locks=majority_of_running # Define a Readwritesplit router [Splitter-Service] type=service router=readwritesplit # Instead of manually listing the servers to route to, use MariaDB Monitor to automatically fetch the list # This is the preferred way to set this up because this lets MariaDB Monitor manage for this router what backends are available cluster=MariaDB-Monitor # Need a backend user for the router, so this sets-up the connection credentials for that user=maxscale password=REPLACE_ME # Reconnect to the primary server if a failover/switchover event occurs mid-session master_reconnection=true # In cases where an in-progress transaction fails to execute on the primary backend, the router can attempt to replay the transaction. This facilitates recovering from a failed Primary without the application realizing anything went wrong transaction_replay=true # Follow this link to learn more about this setting- https://staging-mdb.com/kb/en/mariadb-maxscale-2302-readwritesplit/#master_failure_mode master_failure_mode=error_on_write # This should be set the same as wait_timeout on backend servers. See this link for more details- https://staging-mdb.com/kb/en/mariadb-maxscale-2302-mariadb-maxscale-configuration-guide/#connection_timeout connection_timeout=900s # Configure the router to prefer sending read queries to the backend with the lowest, average response times (this indirectly provides geographic-biased routing which is a good thing so with the same configuration file, our East MaxScale nodes prefer routing to our East MariaDB Server backends, while our West MaxScale nodes prefer routing to our West MariaDB Server backends) slave_selection_criteria=ADAPTIVE_ROUTING # Enable delayed retry to help reduce connectivity-based errors to the application. In short, if MaxScale fails to route a query to a backend because of a connectivity drop, MaxScale can retry sending the query, which is likely to succeed and avoid forcing the application to handle such errors delayed_retry=true delayed_retry_timeout=3s # ServiceNow relies heavily on causal reads, so it is a requirement to be able to send read queries to the primary master_accept_reads=true # Causal reads are required for ServiceNow. This configuration uses global, which is viable if glide.db.url uses the sequential HA mode. If anything other than sequential is used there, this would need to be set to universal instead. If you notice high latency with global, try fast_global instead. Read more at this link- https://staging-mdb.com/kb/en/mariadb-maxscale-2302-readwritesplit/#causal_reads causal_reads=global causal_reads_timeout=3s # Configure MaxScale to listen on the default MariaDB port and to route queries sent there to the Readwritesplit Splitter-Service router [Splitter-Listener] type=listener service=Splitter-Service protocol=MariaDBClient port=3306
Need Help?
While we hope this guide gives you a head start on upgrading your ServiceNow application’s database cluster to support Disaster Recovery and High Availability, we know every deployment brings its own, unique challenges. MariaDB Enterprise Architects would be glad to work with you and your team to solve concerns specific to your deployment, so please feel free to reach out to us.