
MariaDB Xpand is no longer offered. Columnar analytics is currently available via MariaDB Enterprise Server. Please learn more about this offering by visiting: https://staging-mdb.com/products/columnstore/
We recently launched a new version of MariaDB Enterprise that consists of a number of components, including MariaDB Enterprise 10.6, MariaDB MaxScale 6.1 and MariaDB Xpand 6.0. Xpand is MariaDB’s distributed SQL database. It offers built-in HA and linear scalability to millions of transactions per second and huge data sizes.
One of the most exciting new features is the columnar index feature in Xpand 6.0, which enables users to execute certain types of analytical queries much faster allowing you to get real time analytics. And, unlike many other “hybrid” solutions it gives you all the benefits of a relational database – it is strongly consistent and maintains data integrity – while saving customers 90% of their legacy database cost.
What is a columnar index?
In databases (row based databases in particular) indexes are used to find rows quickly based on a particular column value. A classic example for this is using a phone book for finding someone’s phone number. To find the right person you do not have to read every single entry in the phone book. Because it is sorted, you can split the amount of remaining values (persons) in half each time giving you an approximate search time of O(log N) as opposed to O(N) if your phone book was not sorted at all. Normal indexes are built in the same fashion; they have a tree structure that allows the search to discard a large portion of the values at each comparison leading to an approximate search time of O(log n). (Note that most indexes are actually not binary trees, like in the example but instead have more complex structure. Nonetheless the search time follows the same O(log n) curve). As your data size grows exponentially the search time of an index only grows linearly. Indexes can thus greatly increase your search speeds compared to not having indexes.
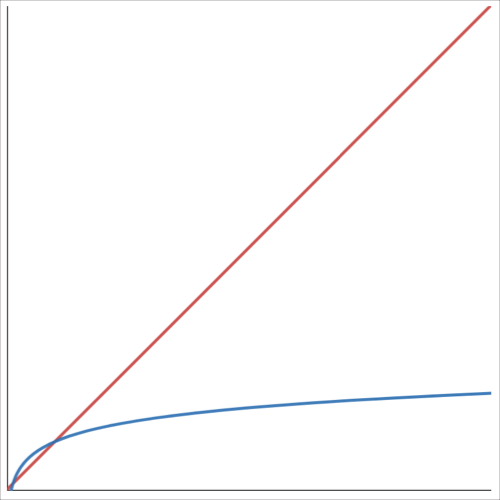
O(n) vs O(log n)
However these types of indexes are not useful for all types of searches. For example when using multiple columns (so called composite indexes) the order of the columns is significant. To get back to the phone book example, the phone book would correspond to an index being created as CREATE INDEX (last_name, first_name). This is great for looking up people if you either know their last name or both their first name and last name. However if you want to find all people with the first name “Michael” such an index is useless. Just like the phone book would be, you would have to look through the whole phone book to find all Michael’s. In order to deal with this problem you typically create more indexes, in our example you could add an index on just (first_name). However the more columns you have and the more different types of searches you need to cater for the more difficult it becomes. In the end you might have a lot more storage taken up by indexes than the actual data and you still haven’t covered all searches.
This is where a columnar index is useful. A columnar index is not aimed at being the fastest for point lookups (a normal index is still more efficient for that), however, a columnar index is aimed at combining multiple different criteria efficiently, independently of in which order they are in the index. So if you want to find all Michael’s that live in the state of Georgia and have a phone number that starts with 6 you can efficiently do that with a columnar index, without having an index specifically designed for that type of search.
Another reason why columnar indexes are very useful is because only the columns actually used in the query, as opposed to the entire row, are being fetched off the disk. The columnar index stores the indexed data in the index and they are structured so that the column values for each such column are streamed in parallel as independent contiguous blocks, rather than reading large volumes of data most of which do not participate in the query.
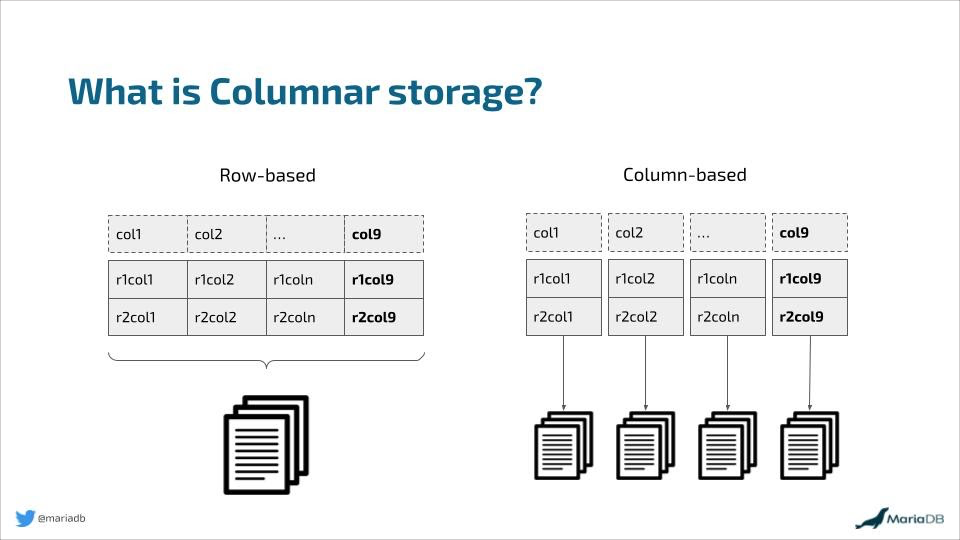
Columnar storage vs row storage. Columnar indexes store the indexed data in a columnar fashion.
This is extremely helpful in cases where you want to aggregate values for a small number of columns but from a large number of rows, which you typically need for analytical type queries. While the difference over having a traditional index and a columnar will hardly be noticeable when you only scan a few rows, when you start scanning millions to billions of rows there is a noticeable difference.
Columnar index is thus a huge benefit for any application which has to do a lot of queries of that type, queries that you otherwise would need a specific analytics database for. This eliminates the need for complex multi-database architectures which try to somehow combine the analytical and OLTP features using continuous replication, and which also exhibit serious problems with data consistency and transactional integrity between the two.
Unlike these, Xpand’s HTAP (Hybrid transactional/analytical processing) solution provides all the desired performance benefits without these drawbacks and without requiring costly and complex application architectures.
Columnar indexes in Xpand
Let’s look at some of the details of the columnar index in Xpand. One typical issue with Columnar indexes is that because of their specific structure, update, delete, and even insert operations become significantly slower (compared to other indexes). To be fair all indexes have the side effect of slowing down writes, the more indexes you have the slower your writes are. However, the regular tree indexes have been optimized for this and the impact is typically negligible (unless you start adding a large number of indexes). To solve this problem we have in Xpand added a structure called a delta store (implemented through B-trees) for rapidly accumulating the writes before actually applying them. The records in the delta store are then transparently and continuously merged into the columnar index in the background. By buffering the changes like this into a delta store, overall I/O is reduced and we are able to have a columnar index with a write ratio sufficiently high for OLTP applications.
At the same time, in order to maintain consistency and transactional integrity, the read operations are combining the information in the delta store with what has already been merged with the full index. Bloom filters (the algorithms which determine definitively that something IS NOT in a given set of records) are used to cut the potential overhead of this additional data structure very significantly.
Using columnar indexes in Xpand
Columnar indexes can be created with the usual syntax for creating indexes, just add the keyword “columnar” in front. Like CREATE COLUMNAR INDEX (column1, column2, column3). As previously mentioned the order of the columns is not significant for a columnar index. You can only have one columnar index per table and should include all columns that this type of index makes sense for. The columnar index is visible in the list of indexes and can be removed (like any index) with the ALTER TABLE DROP INDEX syntax (or just DROP INDEX).
Getting started with columnar indexes in Xpand
If you have a good use case for columnar indexes it is easy to test columnar indexes out. MariaDB Xpand 6.0 is the newest release series and the first one that includes columnar indexes. This release is currently in tech preview so it is currently not recommended for production environments. Customers can download Xpand 6.0 now or give it a spin in MariaDB SkySQL now.