
I suggest you first have a look at my previous post, where I look at the performance of emulated sequences, using an atomic UPDATE and the LAST_INSERT_ID() function. Spoiler: emulated sequences suck performance-wise.
Now I repeat the tests from that post with the native sequences in MariaDB Server 10.3.9.
Changes in the benchmark
With emulated sequences, one needs two SQL statements to insert a new row. First an UPDATE to push the sequence to the next number, then the INSERT itself, using LAST_INSERT_ID() in the VALUES list.
With native sequences we don’t need the UPDATE any more and can use the NEXTVAL() function in the VALUES list. Alternatively you can use NEXTVAL() as DEFAULT value for the column. There is no difference in performance for the last two variants.
Performance
The general benchmark setup is the same as last time. We create a native sequence and a target table. The benchmark script (a Lua script for sysbench) inserts a row into the target table, using the NEXTVAL() from the sequence as primary key. This is repeated in a loop. Optionally this is done in transactions, bundling inserts in batches of 10. The workload is run with different concurrency, starting with 1 benchmark thread and then going up to 128.
The following table shows the insert rate (rows inserted per second) for different thread counts:
| row-by-row | 10 rows per transaction | |||
| threads | sequence | autoinc | sequence-trx | autoinc-trx |
| 1 | 609 | 603 | 3775 | 3751 |
| 2 | 668 | 651 | 5642 | 5554 |
| 4 | 1232 | 1217 | 10027 | 9997 |
| 8 | 2261 | 2240 | 19182 | 19055 |
| 16 | 4129 | 4111 | 35155 | 33879 |
| 32 | 8276 | 8184 | 60200 | 55756 |
| 64 | 16497 | 16303 | 69303 | 62509 |
| 128 | 34456 | 34114 | 65352 | 59954 |
Or you might rather look at a diagram:
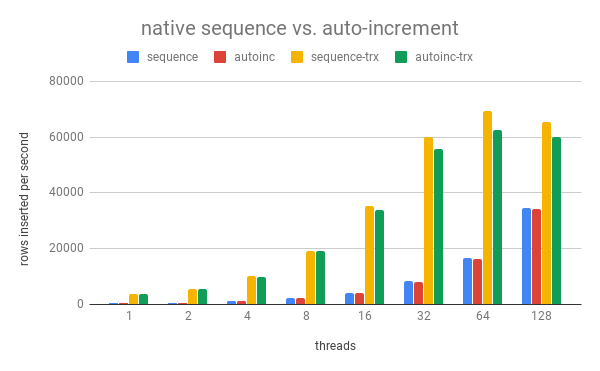
Observations: doing the inserts in transactions of 10 is again faster than inserting row-by-row. This is expected. But we can also see that the native sequence is even faster than auto-increment. This is because a sequence has by default a cache of 1000 while there is no such cache for auto-increment.
When an InnoDB table has to create a new auto-increment value, it must acquire the auto-increment lock for that table. This means that generating auto-increment values is effectively serialized. The sequence needs the same kind of serialization, but in 999 of 1000 cases it can pull the new number from the memory cache. Only in the remaining 1 of 1000 cases the underlying table has to be touched. Hence the sequence scales a tad better. The difference vanishes when we use multiple target tables (and hence multiple auto-increment locks).
Conclusion
The native sequences introduced in MariaDB Server 10.3 deliver excellent performance. At least the same – and in edge cases even better – than auto-increment. Still sequences are more versatile with configurable counting direction and the possibility to use them for multiple tables.
Disclaimer
The benchmarks were run using MariaDB Server 10.3.9, running on a 16-core (32 threads) Intel machine. The datadir was on SSD and MariaDB Server was configured for full durability.
The sysbench implementation is sysbench-mariadb from GitHub. If you look at the numbers from sysbench, keep in mind that the emulated sequence requires two writes to insert one row. So the number of inserts is actually half the number of writes reported by sysbench.
The benchmark scripts, configuration and raw results can be found here.