
A Practical Guide to AI and Vector Search in Relational Databases
01 Executive Summary
Artificial Intelligence (AI) is no longer a future-facing experiment–it is already transforming how enterprises operate. And at the core of many AI-powered applications lies a new requirement: vector search.
From agentic AI systems to recommendation engines, knowledge bases and semantic document search, these capabilities rely on storing and querying vector embeddings–not just traditional rows and columns. Vector search enables applications to retrieve results based on meaning and similarity, rather than exact matches.
Until recently, implementing vector search meant introducing a separate vector database alongside your primary relational system. That added architectural complexity, increased operational burden, and introduced new integration risks.
But that’s starting to change.
Relational databases are evolving to support vector search natively. This allows organizations to unify structured queries and similarity search within a single platform–bringing AI capabilities closer to production systems and reducing the distance between experimentation and deployment. This guide offers a practical introduction to vector search: what it is, why it matters, and where it fits into a modern enterprise data strategy. We will explore key technical considerations–from indexing strategies to hybrid query patterns–and help you understand when a relational database with integrated vector support (like MariaDB Enterprise Platform) is the right choice, and when a specialized vector engine may still be necessary.
If you are planning to extend your existing infrastructure to support AI workloads, this guide will help you navigate the trade-offs, use cases and implementation patterns that matter most for scaling vector search in the enterprise.
- Vector search helps AI applications understand meaning and context, moving beyond traditional keyword matching to power features like personalized recommendations and intelligent chatbots.
- Modern relational databases are now integrating vector search natively, which simplifies your system architecture by unifying traditional data queries with AI-driven similarity searches in a single platform.
- By using a relational database with built-in vector search, like MariaDB Enterprise Platform, you can deploy AI capabilities faster and more efficiently, leveraging your existing SQL expertise and reducing operational overhead.
02 Understanding Vector Search in AI
Traditional search systems rely on matching keywords or structured values. While effective for the exact queries, they fall short in capturing meaning, intent or context. These are essential capabilities for modern AI applications. Vector search addresses this limitation.
At the core of vector search are vector embeddings, which are numerical representations of data produced by machine learning models. These embeddings map text, images or other content into high-dimensional space where proximity reflects semantic similarity.
Two customer support tickets, for example, may be phrased differently but lie near each other in vector space if they describe the same underlying issue. A vector space is simply a (very) high-dimensional grid. Each embedding is a point in that grid, so items with similar meaning cluster together.
A vector search system enables queries such as “find transactions similar to this one” or “retrieve documents related in meaning to this paragraph.” Instead of exact matching, it ranks results by the distance between vector representations, using algorithms such as cosine similarity or Euclidean distance.
In practice, vector search is
commonly used to power:
Personalized recommendations based on user behavior or preferences
Semantic document retrieval, using embeddings to locate conceptually related information
Conversational AI,
where context
embeddings help refine chatbot responses
Some production systems benefit from a hybrid of search and query, where structured filters such as user segment, timestamp or product category combine with vector similarity. This approach enables use cases that are both operationally grounded and semantically rich.
By incorporating vector search directly into commonly used relational databases, organizations can support these workloads without introducing new infrastructure. Vector-enhanced queries can run alongside traditional SQL, unlocking AI capabilities within familiar systems and tooling.
03 Core Database Considerations for Vector Search
Vector search introduces a new class of query that prioritizes semantic similarity over exact matches. While conceptually simple, implementing vector search at scale raises distinct challenges for database systems. Performance, indexing and integration with existing query workflows are all key factors in choosing the right approach.
Performance and Scalability
Unlike traditional indexes that support equality or range scans, vector indexes are optimized for approximate nearest neighbor (ANN) search. These algorithms trade perfect accuracy for speed, enabling real-time similarity queries even over large datasets.
Three approaches are commonly used:
HNSW (Hierarchical Navigable Small Worlds):
A graph-based index that offers fast search performance and high recall. It requires significant memory but performs well for low-latency applications.
IVFFlat (Inverted File with Flat Vectors):
AA cluster-based method that balances indexing time and search efficiency. It can scale to large datasets but may require tuning.
Brute-force search:
An exhaustive method that guarantees exact results. While accurate, it is computationally expensive and typically reserved for small datasets or offline scoring.
Vector search systems must also support concurrent access patterns, particularly when integrated into transactional applications. For example, some workflows may require hundreds of similarity queries per second running alongside inserts, updates and analytic reads.
Storage and Embedding Management
Vector embeddings are often stored as arrays of 32-bit floating-point numbers, or occasionally quantized to smaller sizes for performance. Managing these representations at scale still calls for compact storage formats and smart indexing strategies. Some systems compress or quantize vectors; others prioritize fast reads for low-latency inference.
Databases must also support insert/update operations at rates that match upstream AI pipelines. For example, product catalogs, behavior logs or transaction histories may generate embeddings continuously.
Integrated vs. Plug-in Architectures
Some vector systems are built as extensions on top of general-purpose databases. Others are integrated in the general-purpose database. Integrated implementations often deliver better performance because they connect directly with the storage engine, optimizer and indexing system.
For example, MariaDB Enterprise Platform includes integrated vector indexing, which offers tighter integration and better concurrency compared to plug-in models layered onto PostgreSQL.
Hybrid Vector and SQL Integration
Many use cases combine structured filters with similarity search. A typical query might filter by user type, product category or date, and then rank results by vector distance. Support for hybrid queries–combining relational predicates and ANN retrieval–is essential for practical applications.
MariaDB Enterprise Platform example query:
E-commerce
Show me ten jackets like this, under $200, that are in stock.
SELECT product_id, name, price
FROM products
WHERE category = 'Jackets'
AND price < 200
AND in_stock = TRUE
ORDER BY VEC_DISTANCE(embedding, ?) -- bind query vector here
LIMIT 10;
Customer Support
Find recent tickets like this one from premium customers.
SELECT ticket_id, subject, opened_at
FROM support_tickets
WHERE customer_tier = 'Premium'
AND opened_at >= CURRENT_DATE - INTERVAL 30 DAY
ORDER BY VEC_DISTANCE(ticket_embedding, ?) -- bind new-ticket vector
LIMIT 5;
Knowledge Base
Retrieve articles similar to this question, for product “MariaDB Enterprise Platform”, published in the last six months.
SELECT doc_id, title, published_at
FROM kb_articles
WHERE product = 'MariaDB Enterprise Platform'
AND published_at >= CURRENT_DATE - INTERVAL 6 MONTH
ORDER BY VEC_DISTANCE(article_embedding, ?) -- bind paragraph vector
LIMIT 15;
Media Streaming
Find ten action movies like this one, rated PG-13, released after 2015.
SELECT movie_id, title, release_year
FROM movies
WHERE genre = 'Action'
AND rating = 'PG-13'
AND release_year >= 2015
ORDER BY VEC_DISTANCE(movie_embedding, ?) -- bind seed-movie vector
LIMIT 10;
Talent Search
Show candidates whose résumés resemble this profile, located in the United States, with ≥ 5 years experience.
SELECT candidate_id, full_name, years_experience, last_active
FROM resumes
WHERE VEC_DISTANCE(resume_embedding, ?) < 0.35 -- strict similarity cut-off
AND country_code = 'US'
AND years_experience >= 5
ORDER BY last_active DESC -- secondary sort
LIMIT 12;
These examples highlight how MariaDB combines relational predicates with approximate-nearest-neighbor ranking in a single query plan. You get fast similarity search, traditional SQL guarantees, and none of the operational overhead of running a separate vector database.
04 Use Cases Where General-Purpose Databases with Vector Search Excel
While standalone vector databases are designed for large-scale semantic retrieval, many production use cases involve structured data, operational requirements or existing SQL infrastructure. In these cases, embedding vector search directly into a relational database reduces complexity, simplifies integration and accelerates deployment.
The following examples highlight use cases where integrated vector capabilities in SQL databases–such as MariaDB Enterprise Platform–offer practical advantages.
Enterprise Knowledge Retrieval
Internal documentation, wikis and support content often span teams and formats. Traditional keyword search struggles to surface semantically relevant material. By embedding content and user queries into vectors, enterprises can return results that match meaning, not just wording.
Storing and querying embeddings within the same database that holds document metadata allows filtering by team, department or date while ranking by relevance.
E-commerce Product Recommendations
Recommender systems often rely on the similarity between products, user preferences or session behavior. Embeddings representing these relationships can be queried via vector search to deliver “similar items” or “users also viewed” recommendations. Housing this logic inside a relational database simplifies inventory filtering, localization and personalization logic.
Customer Support AI Assistants
Retrieving relevant prior cases is essential to powering AI assistants and human support agents. Embedding past tickets and support content enables retrieval by similarity to new queries. Coupling vector ranking with structured metadata (e.g., product type, customer tier) supports high-accuracy results within a support workflow.
05
When Might You Use a
Specialty Database
Different databases have different vector search features. For instance, MariaDB’s built-in vector functions cover the common “ANN-plus-SQL” pattern well enough for most production workloads. If your search requirements demand IVF-PQ, HNSW with dynamic edge pruning, sub-vector product quantization, or tight control over code-book retraining intervals, you may need to consider a specialty database. Even in such a case, you will likely want to use a mix of both a general-purpose database and a specialized database. The relational layer can still own metadata, joins and transactional guarantees, and the specialty database can handle your particular vector algorithm.
06
Implementing Vector
Search in SQL Databases
Embedding vector search directly into a SQL database enables hybrid search within familiar data environments. This reduces infrastructure sprawl and brings AI-powered capabilities closer to the systems where operational data lives. Successful implementation involves embedding management, index optimization and careful query design.
Storing and Querying Vectors
Vector data is typically stored as fixed-length arrays of 32-bit floats. SQL databases with integrated vector support treat these as a dedicated data type, allowing direct insertion, indexing and querying.
Example
Inserting an embedding into a table:
INSERT INTO knowledge_base (id, content, embedding)
VALUES (101, 'How to enable SSO', VEC_FROM_TEXT('[0.13, 0.48, 0.91, ...]'));
Example
Querying for similarity:
SELECT id, content
FROM knowledge_base
ORDER BY VEC_DISTANCE(embedding, VEC_FROM_TEXT('[0.12, 0.49, 0.90, ...]'))
LIMIT 3;
Some databases also support direct integration with Python or API-generated embeddings, allowing application logic to pass vectors at query time.
Indexing for Performance
For large-scale workloads, vector indexing is essential. Approximate nearest neighbor indexes like HNSW provide sublinear search performance with high recall. These indexes can be configured based on application needs–larger graphs improve accuracy but require more memory.
Best practices include:
- Choosing indexing parameters appropriate to your query load
- Ensuring sufficient memory to keep indexes in-memory for fast access
- Periodically rebuilding indexes when embedding distributions shift
Considering Recall
Many databases tout their overall performance with vector search, however, a key aspect of your consideration of any benchmark or claim should be the recall setting used.
0.8 to tune for responsiveness might be enough for UI previews, recommendations, etc.
0.9 is a good starting point for most production use cases.
0.95 is usually safer for RAG (retrieval-augmented generation) style AI applications to reduce hallucinations.
What “recall” actually means in this context:
In vector search, “recall” usually refers to how closely the ANN algorithm matches the exact nearest neighbors (ground truth).
For example:
- If the top 10 ground-truth neighbors are {a, b, c, …, j}
- And your ANN algorithm returns {a, b, c, d, f, h, i, j, k, l}
- Then recall@10 = 8 / 10 = 0.8
In general, using a setting less than 0.8, while it can produce impressive results for benchmarks, produces results that are not acceptable for real-world, production use cases.
Hybrid Search and SQL Filtering
One of the main advantages of implementing vector search in SQL is the ability to combine similarity search with structured filters.
Example
Retrieve support tickets similar to a given issue, filtered by product version and priority:
SELECT id, title
FROM support_tickets
WHERE product_version = '2.1'
AND priority = 'High'
ORDER BY VEC_DISTANCE(embedding, VEC_FROM_TEXT('[...]'))
LIMIT 5;
This tight integration supports contextual AI retrieval without needing to pipeline across multiple systems.
Embedding Management
Efficient embedding storage and lifecycle management are essential. Teams should:
Keep vector dimensions consistent within each modality (e.g., 384-D for text, 512-D for images); for mixed-modality datasets, use separate indexes or pad/truncate as needed to align dimensions before similarity search (this must be done carefully to avoid information loss or misalignment)
Version and tag embeddings where multiple model types or sources are used
Embedding pipelines are often managed outside the database by data science or MLOps teams, with vector storage handled via SQL inserts or batch jobs.
Implementing vector search in SQL databases enables AI-driven capabilities while preserving the consistency, security and extensibility of relational systems. For teams already operating on SQL, this approach offers a fast, low-friction path to production and a future-proof foundation that scales naturally as workloads, data volumes and embedding modalities and use cases grow. Because vectors live alongside traditional tables, teams can reuse proven sharding, replication and governance patterns instead of migrating to a separate store later.
The Future of AI-Powered Search
in Enterprise Databases
As AI adoption continues to expand across industries, the ability to integrate machine learning-driven search into core operational systems will become a baseline capability–not a niche feature.
Enterprises are already applying semantic search to structured workflows like product catalogs, support cases, financial logs and customer interactions. What began as a function of specialized vector databases is now moving into the relational core.
Integrated Vector Support
Becomes Table Stakes
Just as databases evolved to support full-text search, spatial data and JSON, integrated support for vector embeddings is now following a similar path. Rather than forcing users to manage separate vector systems, modern databases are beginning to offer:
Built-in vector
data types for storage
and indexing
Native ANN indexes optimized for similarity search
Integration with standard SQL query planning and execution
This convergence simplifies deployment, reduces architectural complexity and brings AI workflows closer to where enterprise data already lives. This shift requires embedding diverse data and querying it within a unified framework. Databases capable of supporting embeddings and structured queries will play a critical role in these pipelines.
AI Workflows Inside the Database
As vector operations become more common, the distinction between AI workflows and operational databases continues to narrow. Already, some platforms allow AI models to generate and insert embeddings directly into the database. Others support calling external APIs or embedding services from within application logic.
Going forward, we can expect:
- Closer coupling of AI model output and vector storage.
- Embedding pipelines run inside your existing ETL or CDC jobs. Each new or updated row flows through the model, and the fresh vector is written back right away.
- Operational inferences powered by vector queries at runtime. For example, when a competitor updates the price of an item, not only can an e-commerce retailer update the price for the same item—but similar items as well (i.e., all generic pasta makers similar to the updated one).
These capabilities will enable applications to move from search-as-a-feature to search-as-intelligence, where results are personalized, contextual and deeply integrated into user experience.
AI Workflows Including the Database
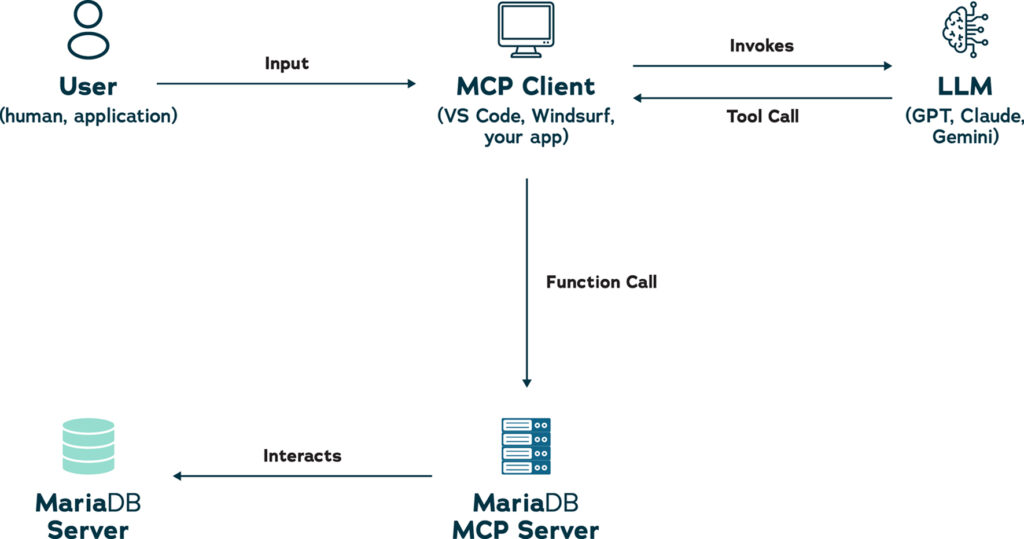
AI models like OpenAI’s GPT, Anthropic’s Claude, and others already are excellent tools for writing applications. With the help of the Model Context Protocol (MCP), AI models can invoke external services and even execute code, including code that runs in your database. This enables developers to expose database access to LLMs in a controlled way. Natural language input is mapped to structured SQL through secure function calls, making it possible for
models to query, update and interact with the database using secure function calls exposed by an MCP Server.
In general, an MCP server exposes predefined function calls to backend logic, APIs or databases. Using MariaDB as an example, the following diagram illustrates the concept:
07
Conclusion and
Strategic Recommendations
Vector search is no longer an experimental capability reserved for specialized AI teams. It is becoming a foundational component of enterprise applications that are adding contextual, semantic and personalized experiences.
The challenge for most organizations is not whether to adopt vector search, but how to do so without adding unnecessary complexity. In many cases, the answer lies in extending existing relational databases to support vector embeddings and similarity queries.
SQL databases with integrated vector capabilities provide a practical path forward. They enable hybrid search patterns, support structured filtering alongside ANN indexing and reduce the overhead of managing multiple data systems. This makes them well-suited to use cases like semantic document retrieval, product recommendations and AI-assisted support.
Enterprises evaluating vector search should consider:
- Proximity to existing data: Can vector search be performed where your operational data already resides?
- Query complexity: Do your workloads require hybrid structured and semantic filtering?
- Team workflows: Can developers, DBAs and data scientists collaborate more easily within a unified platform?
By aligning search architecture with these practical realities, organizations can deploy AI-powered search faster, more efficiently and at lower cost.
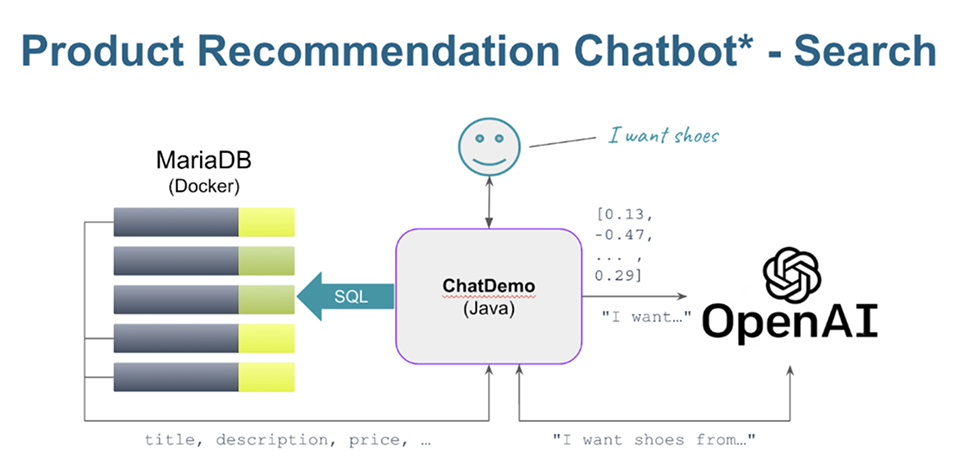
MariaDB’s Vector Embedded Search: See It in Action
Unlock the power of MariaDB Enterprise Platform and its vector capabilities using a full vector search demo. In this demo you chat with the OpenAI API (the programmatic model behind ChatGPT) and connect its output to products in a local MariaDB instance. To check it out, clone:
https://github.com/alejandro-du/mariadb-rag-demo-java
and follow the instructions.
08
MariaDB Enterprise Platform:
A Comprehensive Solution
for Modern Data Demands
MariaDB Enterprise Platform delivers an end-to-end database solution built for modern workloads. Supporting both transactional and analytical use cases, it unifies structured and semi-structured data (relational and JSON) in a single platform that runs seamlessly across on-prem, cloud and hybrid environments. Organizations can streamline infrastructure, reduce sprawl and build applications faster using one powerful system for all workloads.
MariaDB Enterprise Platform is engineered for high availability, disaster recovery and production-grade performance. Whether through automatic failover, read scaling or multi-writer clustering, the platform keeps data available and operations running smoothly–even in the face of failure. Enterprise customers also benefit from end-to-end encryption, fine-grained auditing and integration with external security systems like HashiCorp Vault.
MariaDB brings vector search, transactional and analytical workloads together in one database. Built-in replication, columnar storage and distributed scale-out keep similarity queries fast and throughput high. You avoid the licensing fees of closed-source databases and skip the complexity of running a separate vector store. Your team keeps its SQL skills and tooling while moving AI workloads into an enterprise-grade platform designed for growth.
As part of MariaDB’s commitment to an end-to-end platform, MariaDB Enterprise Server, the core database that’s part of MariaDB Enterprise Platform, now includes integrated vector search, turning MariaDB into a relational + vector database. This lets you perform similarity search directly inside the same database you use for transactions and analytics–no bolt-on vector engine required.
With MariaDB databases, developers can run semantic search, filtering and hybrid queries (SQL + vector) using familiar tools and interfaces. Because it’s embedded, vector search benefits from all the platform’s reliability, security and scalability–avoiding the added complexity, latency and cost of external vector databases.
Practical Applications of Vector Search
Enterprise Knowledge Retrieval
Improve internal search and decision-making by finding semantically relevant documentation, wikis and historical customer data across large corpora.
E-commerce Product Recommendations
Use real-time
behavioral and product
similarity vectors to
deliver highly personalized shopping experiences and
increase conversion.
Customer Support AI Assistants
Retrieve the most relevant historical cases or solutions using vector search, enabling generative AI assistants to respond more accurately and efficiently.
By embedding vector search directly into its platform, MariaDB empowers enterprises to build AI applications while maintaining the performance, reliability and simplicity of a single database solution. It’s the AI-powered database that delivers real-world results–without the enterprise price.
Contact Us to Learn More About MariaDB