
It is not hyperbole to say that sharding saved the Internet as we know it. First, manually partitioning the database and running queries on multiple servers. Next, auto partitioning data and evenly distributing the load. However, web traffic has exploded over the last year, let alone the last decade. Systems of record that used to run “in the back office” are now on the web, and the amount of data processed is beyond the capabilities of mere sharding. Next, polyglot persistence has yielded the trouble of maintaining several different databases. Sharding and polyglot was the booster rocket we needed to get to the roaring 20s, but it will not take us to cloud scale.
The internet was built on MySQL and later MariaDB. In the early days of the Internet, these technologies scaled well enough and provided the robust database functionality that developers needed for real web applications. However, the web grew, the amount of data generated increased, and how we use the web changed. Our expectations also changed. It is no longer acceptable to take a site down for hours at a time for routine maintenance. In the early web, it was okay because customers could just dial in later.
NoSQL databases emerged and promised us “web scale,” but there was a cost. Databases had to give up joins, transactions, and other functionality that developers had taken for granted. In essence, the database could scale as long as it did not do very much. However, if you are launching an early social media site with high traffic and data volume but people are just looking at their own profile and those of a couple of their friends, then you need scale, not robust functionality. If you are keeping a giant movie catalog and updates are relatively rare – no problem.
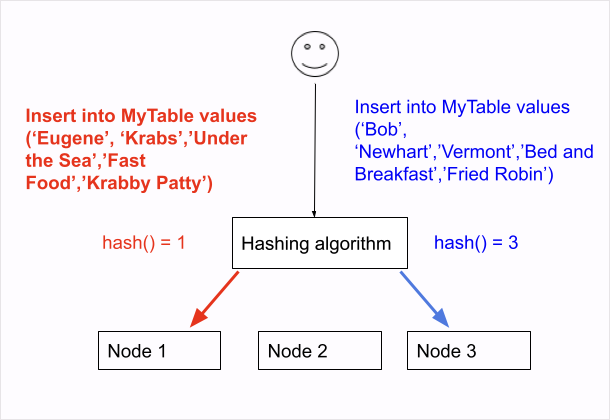
Key to NoSQL scalability was the ability to split the data or “shard” it. Most sharding is done today with either hashed sharding or range sharding. These have different advantages and disadvantages but allow more nodes to process more data. Fundamentally they both use some subset of the fields to calculate a distribution or shard key and then use that to place the data on a node.
Hash sharding is “fair” and will result in the most even distribution of data. Based on the hash key, the row is distributed to a node in the cluster. Range sharding distributes data, but close values are likely to be on the same node. Range sharding is less “fair.” If I put last names in my shard key, then the node carrying “S%” is going to get more load, but when a query asks for everything “S%” related, it will probably be a sequential read (or maybe a couple of them).
Sharding is essential for cloud scale applications, but it is not enough. Meanwhile, customers and modern business now demand everything be available at any time. Anything can fail anywhere, at any time, and the system has to deal with it. On many NoSQL systems, those failures essentially cause outages or at least the inability to write while a new primary is elected and the data is rebalanced.
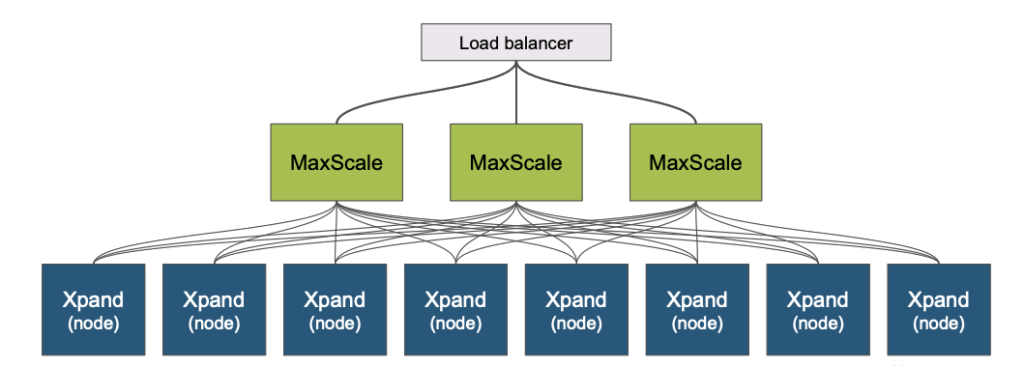
The secret to cloud scale is assuming that these bad things are happening all the time. In fact, If you have a large enough network, then every bad thing is always happening at once at all times. That is why distributed SQL databases like MariaDB Xpand and its cloudy cousin MariaDB SkySQL are different. By adding group membership and a consensus protocol (Paxos) to the mix, changes and errors are managed efficiently. A read or write can take place on any node and is coordinated throughout the cluster. The database automatically handles failures and rebalances. No wait is required.
Additionally, genuine transactions are a must. The reasons are twofold. First, the types of workloads have changed. There is no more “Back Office.” The cloud is the back, middle and front office. Real applications require real guarantees of consistency. Secondly, when you distribute data across the network at scale, those expected failures require a means of ensuring consistency for the whole database. “Eventual” consistency is not good enough for applications with critical data and not good enough at a scale where failure somewhere is not just possible but probable.
Next, the modern cloud must endure “spikey” traffic. The classic example is “Black Friday,” but in 2020, “Black Friday” web traffic was three months long, starting in March and not just for retail. Suddenly there are a lot of database requests, and more capacity is needed. The database must rapidly expand to more nodes and distribute the load. Just as quickly, the traffic evaporates, and maintaining double the normal number of nodes makes no sense. Modern data infrastructure must not just scale out but scale back without an outage or data loss.
So sharding got us here. NoSQL may have even saved the web. However, it is not enough for cloud scale or modern applications. The new data infrastructure must scale up, scale back, guarantee consistency, balance load and do so quickly without downtime. That data infrastructure sounds a lot like MariaDB Xpand or SkySQL.
Try it now
Whether you are looking for a public cloud SaaS database that scales horizontally or runs in your private cloud, MariaDB has you covered. Xpand can run in your data center or the public cloud. SkySQL offers a full database-as-a-service version of Xpand in the public cloud. It goes without saying that both are fully compatible with MySQL and MariaDB. You can try SkySQL right now using your Google, GitHub, or LinkedIn account or sign up for a free trial of Xpand in your own datacenter.
And if you’d like to dive deeper on the topic of sharding and distributing database workloads under scale, join this webinar.