
Reactive Programming seeks to solve scalability challenges in modern applications. These challenges are typically characterized by the inefficient use of computing power (CPU) and memory in huge thread pools. The paradigm focuses on performing calls to I/O operations in a non-blocking fashion. A reactive system doesn’t block threads during calls to external systems such as web services and databases.
There are a multitude of frameworks and libraries that enable Reactive Programming in Java. Reactor, for example, is a library for implementing reactive applications using the Reactive Streams interfaces. R2DBC is a specification that takes the Reactive Programming paradigm to the SQL world, enabling the development of fully-reactive Java applications that consume relational databases.
Being fully-reactive is key. If your application blocks a thread during a request (for example from the browser to a REST web service), there’s little to gain from Reactive Programming. Moreover, the opposite could be true–you might see a performance penalty by mixing blocking and non-blocking calls.
In this article, I introduce you to the world of Reactive Programming using Spring Data R2DBC on MariaDB SkySQL.
What is reactive programming?
Here’s an analogy. Let’s say you have an appointment with a busy person. You arrive at their office and they have a secretary that tells you “please, wait.” You then sit down and wait for the person to meet you. That’s the “traditional” programming paradigm:

Now, let’s imagine a different situation. You arrive and the secretary tells you “I’ll call you back.” You might well say “thanks, I’ll go do something else meanwhile.” That’s the Reactive Programming paradigm:

The fundamental difference between the traditional and the reactive approach is that in the reactive approach, you can do something else than waiting. In the context of software applications, this means that a thread or a processor can perform other tasks while an I/O operation is being executed.
Not every application or every request handled by an application can “do something else” while an I/O operation is taking place. This is why Reactive Programming is no silver bullet. Reactive Programming introduces its own software constructs that make debugging and testing a bit more difficult than with the traditional approach. However, if you have the right use case for Reactive Programming, you’ll see important gains in throughput which is what you should measure when comparing blocking vs. non-blocking services. Don’t measure service time. Why? Here’s why:

Regardless of whether you sat down and waited or went somewhere else to do something else, you’ll meet this person at the same point of time in the future. Remember, the difference is whether you performed extra work or just waited.
If you want to learn how to compare the performance of reactive vs traditional services, take a look at the Reactive Programming with Reactor and R2DBC webinar, where I explain these concepts in more detail and show you how to run load tests to compare a JDBC/Servlet-based REST web service against one based on Reactor/R2DBC.
Setting up the database
We need a database running outside our development machine. The reason for this is that we want to free computing resources to take advantage of the parallel processing that can occur while we make non-blocking calls. You can use a local database and still see a performance improvement (remember, on throughput not on service time), but I strongly recommend using a separate machine or an external service such as SkySQL if you plan to test a service to evaluate whether Reactive Programming is a good fit for it.
Go to the SkySQL Portal, create a free account (no credit card required), and log in. There are detailed instructions in the MariaDB docs site, in case you need them. Launch a new service:

Feel free to use any configuration you want. I recommend the following:
- Service type: TRANSACTIONS
- Topology: SINGLE NODE
- Cloud provider: (pick your favorite)
- Instance size: (the smallest is enough)
- Storage size: 100
- Server version: (latest)
Give it a name and launch the service. This will create a MariaDB database in the cloud. While the service is being created, download a SQL database client tool like DBeaver, HeidiSQL, or DataGrip, if you haven’t already. You can also use your IDE’s SQL functionality if you prefer. You can also use the mariadb CLI tool if you prefer. Before using any of these tools to connect to the MariaDB database, add your IP address to the allowlist. You’ll find an option to automatically detect and add your current IP address in the Security Access option of the configuration menu:
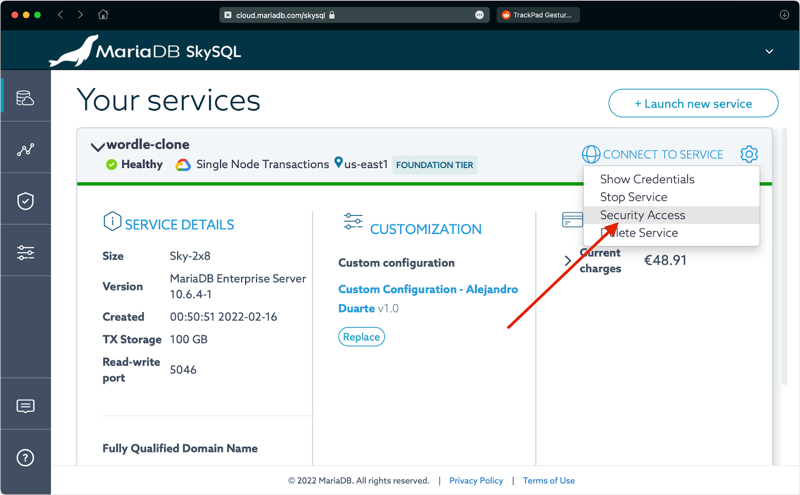
Click on Add my current IP address and then on Done. Danger zone: If you want to connect from anywhere, add an entry with the value 0.0.0.0/0.
Click on CONNECT TO SERVICE and download the certificate authority chain file (skysql_chain.pem). Any computer that tries to connect to this MariaDB database must have the certificate in the file system. Keep the file somewhere safe in your hard drive. You’ll see all the connection details in this dialog as well. You’ll need:
- Host (you can find it under Connect using MariaDB CLI)
- Port
- User
- Password
Now you have all the ingredients. Use the SQL client of your choice and connect to the MariaDB database. Create a new connection and use the values reported in SkySQL Portal. Additionally, you have to specify two driver properties:
useSsl=trueserverSslCert=/path/to/your/skysql_chain.pem
If your SQL client allows you to specify a JDBC connection string, you can pass the properties as follows:
jdbc:mariadb://demo-db0000xxxx.mdb000xxxx.db.skysql.net:5047?useSsl=true&serverSslCert=/path/to/your/skysql_chain.pem
Once connected to the instance, create a new database and table:
CREATE DATABASE reactive-demo; CREATE TABLE word ( id INT PRIMARY KEY AUTO_INCREMENT, text VARCHAR(64), );
We also need to insert test data. There are many options, and I’ll leave this as an exercise to you. Explore tools like generatedata.com or mockaroo.com and create 500-1000 rows or more and insert them into the word table. You can also try to download a data set and use a LOAD DATA LOCAL INFILE sentence to save the data in the SQL table. See this GitHub repository for an example.
Creating a Spring Boot project
Create a new project using the Spring Initializr. Use the following dependencies and configuration:
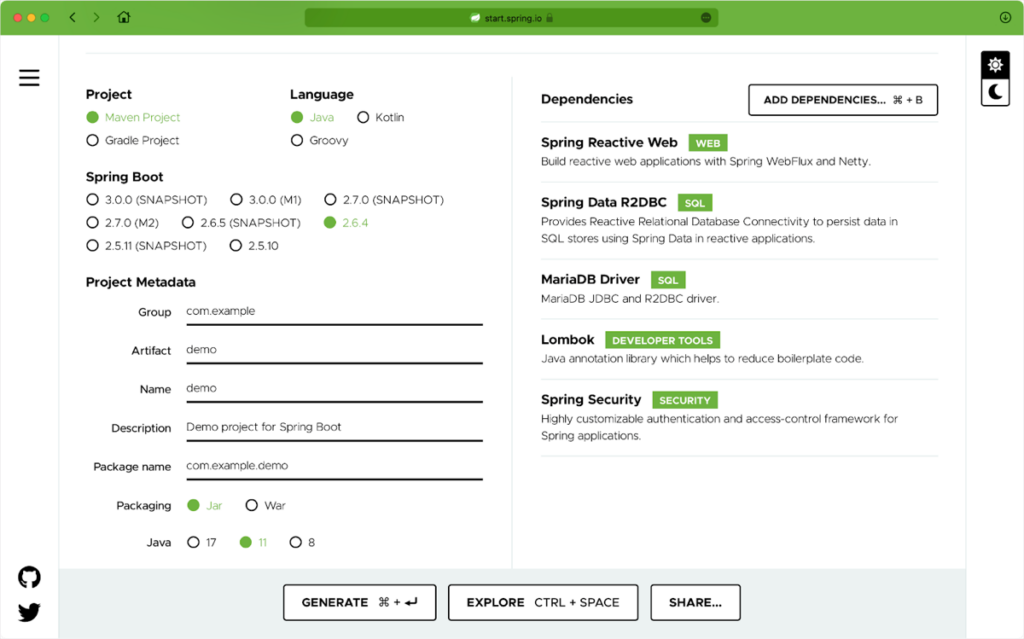
Generate the project, extract the ZIP file, and import the Maven project into your IDE.
If you are on a Mac, add the following dependency to the pom.xml file:
<dependency> <groupId>io.netty</groupId> <artifactId>netty-all</artifactId> <optional>true</optional> </dependency>
Implementing a reactive repository
Create a Word class to encapsulate the data from the database:
import lombok.Data;
import org.springframework.data.annotation.Id;
@Data
public class Word {
@Id
private Long id;
private String text;
private String data;
}
Keep in mind that this is not a JPA Entity. We are not even using JPA in this project. JPA depends on JDBC which performs blocking calls to the database. Instead, we are using R2DBC which is non-blocking. Spring Data R2DBC makes it simple to create data repositories that use R2DBC-compliant drivers like the one provided by MariaDB.
Create a new interface with an SQL query that returns a specified number of words from the database:
import org.springframework.data.r2dbc.repository.Query;
import org.springframework.data.r2dbc.repository.R2dbcRepository;
import reactor.core.publisher.Flux;
public interface WordRepository extends R2dbcRepository<Word, Long> {
@Query(value = """
SELECT id, text
FROM word
ORDER BY RAND()
LIMIT :limit
""")
Flux<Word> findWords(int limit);
}
Notice the use of the RAND() SQL function to get random rows. See that the method returns a Flux object. A Flux is a stream of data. Clients of this interface can subscribe to this stream of data to use it as it is emitted without blocking the thread that subscribes to it.
Implementing a reactive REST service
Create a new class as follows:
import lombok.RequiredArgsConstructor;
import org.springframework.http.MediaType;
import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
@RequestMapping("/")
@RequiredArgsConstructor
public class WordService {
private final WordRepository wordRepository;
@RequestMapping(value = "/words", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<Word> findWords(@RequestParam int limit) {
return wordRepository.findWords(limit)
.map(this::fillData);
}
private Word fillData(Word word) { // simulates work
BCryptPasswordEncoder encoder = new BCryptPasswordEncoder();
String encoded = encoder.encode(word.getText());
word.setData(encoded);
return word;
}
}
This is a simple REST controller that uses the repository we previously created, and that produces data of type text/event-stream. This makes it possible for web clients (like web browsers) to implement a reactive UI that doesn’t block the execution of code. The class also declares a method to simulate work. Instead of returning the data as-is from the database, we are processing it using the fillData(Word) method. Remember “I’ll go do something else?” This is something else that the CPU can do while the data is being gathered from the database. The BCryptPasswordEncoder class uses processing power to encode data. Perfect for our purposes of simulating work. You could have used Thread.sleep(long) as well, but using something that actually makes the processor busy makes more sense when you want to compare the performance of services.
Connecting to SkySQL
To connect to SkySQL using the MariaDB R2DBC driver, we use a connection string that resembles the one you’d use with JDBC:
r2dbc:mariadb://demo-db0000xxxx.mdb000xxxx.db.skysql.net:5047/reactive-demo?sslMode=VERIFY_CA&serverSslCert=/path/to/skysql_chain.pem
In the application.properties file, add the following properties to configure the connection to the SkySQL service (use your own configuration values):
spring.autoconfigure.exclude=org.springframework.boot.autoconfigure.security.reactive.ReactiveSecurityAutoConfiguration spring.r2dbc.url=r2dbc:mariadb://demo-db0000xxxx.mdb000xxxx.db.skysql.net:5047/reactive-demo?sslMode=VERIFY_CA&serverSslCert=/path/to/skysql_chain.pem spring.r2dbc.username=some_username spring.r2dbc.password=some_password spring.r2dbc.pool.max-size=10 spring.r2dbc.pool.max-create-connection-time=10s
The first line disables Spring Security (we added Spring Security only to be able to use the BCryptPassword class). The last two lines show how to configure the connection pool. Use the same values if you plan to compare with a JDBC-based service.
Requesting the service
The easiest way to request the service is to use a web browser. Request, for example, 50 words by pointing your browser to:
http://localhost:8080/words?limit=50
Comparing blocking vs. non-blocking services
Try implementing the same service using the Servlet API (instead of WebFlux), and JDBC (instead of R2DBC). Use tools like JMeter or Artillery to load test the services and try to understand when to use Reactive Programming and when not to. For example, vary the number of words requested, or disable the simulated data processing (the fillData(Word) method). Always check throughput instead of service time, for example, by comparing the number of successful requests (HTTP 200).
Learn More
Watch my recorded webinar, Reactive Programming with Reactor and R2DBC, to learn how to compare the performance of reactive vs traditional services.
If you’d like to learn even more about what’s possible with MariaDB be sure to check out the Developer Hub and our new Developer Code Central GitHub organization. There you can find much more content like this spanning a variety of technologies, use cases and programming languages.